YOLO11 自定义目标检测模型训练全流程
从数据标注到模型部署的完整教程——以国标直流充电口检测为例
整体流程概览
环境准备
1.1 创建 Conda 虚拟环境
1.2 安装 Ultralytics
1.3 验证安装
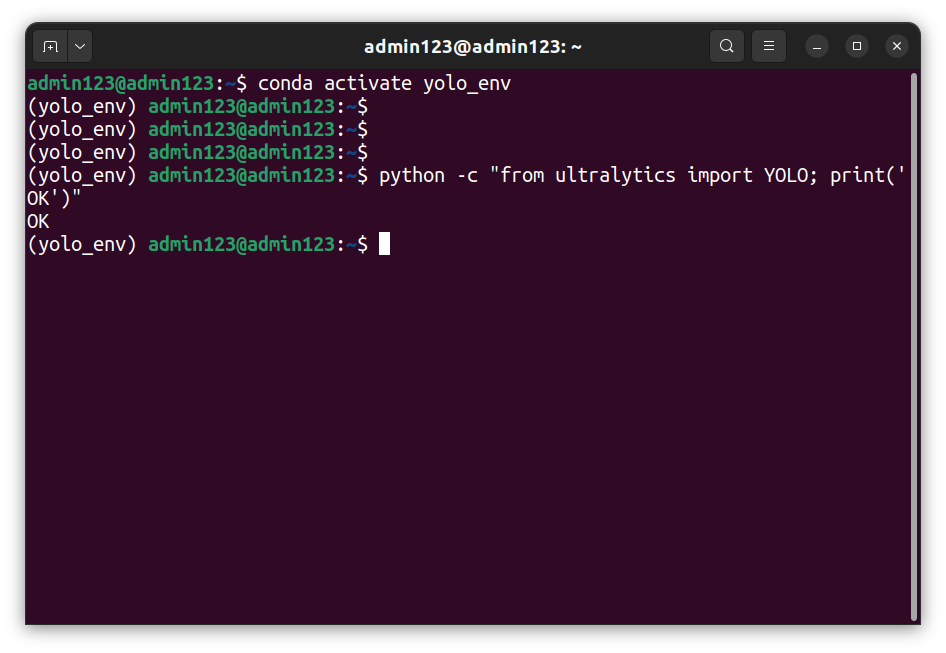
▲ 图 1:Conda 环境创建 + Ultralytics 安装验证成功的终端输出
1.4 下载初始预训练权重
首次运行时 ultralytics 会自动下载,也可手动下载放到项目目录:
手动下载地址:https://github.com/ultralytics/assets/releases,也可用 wget 直接下载:
| 模型 | 参数量 | 适用场景 |
|---|---|---|
| yolo11n.pt | 2.6M | 实时检测,CPU 可用 |
| yolo11s.pt | 9.4M | 精度与速度平衡 |
| yolo11m.pt | 20.1M | 较高精度 |
Roboflow 项目创建与图片上传
2.1 注册并创建项目
- 访问 app.roboflow.com,注册账号并登录
- 点击 New Project
- Project Type 选择 Object Detection
- 填写项目名称,点击 Create Project
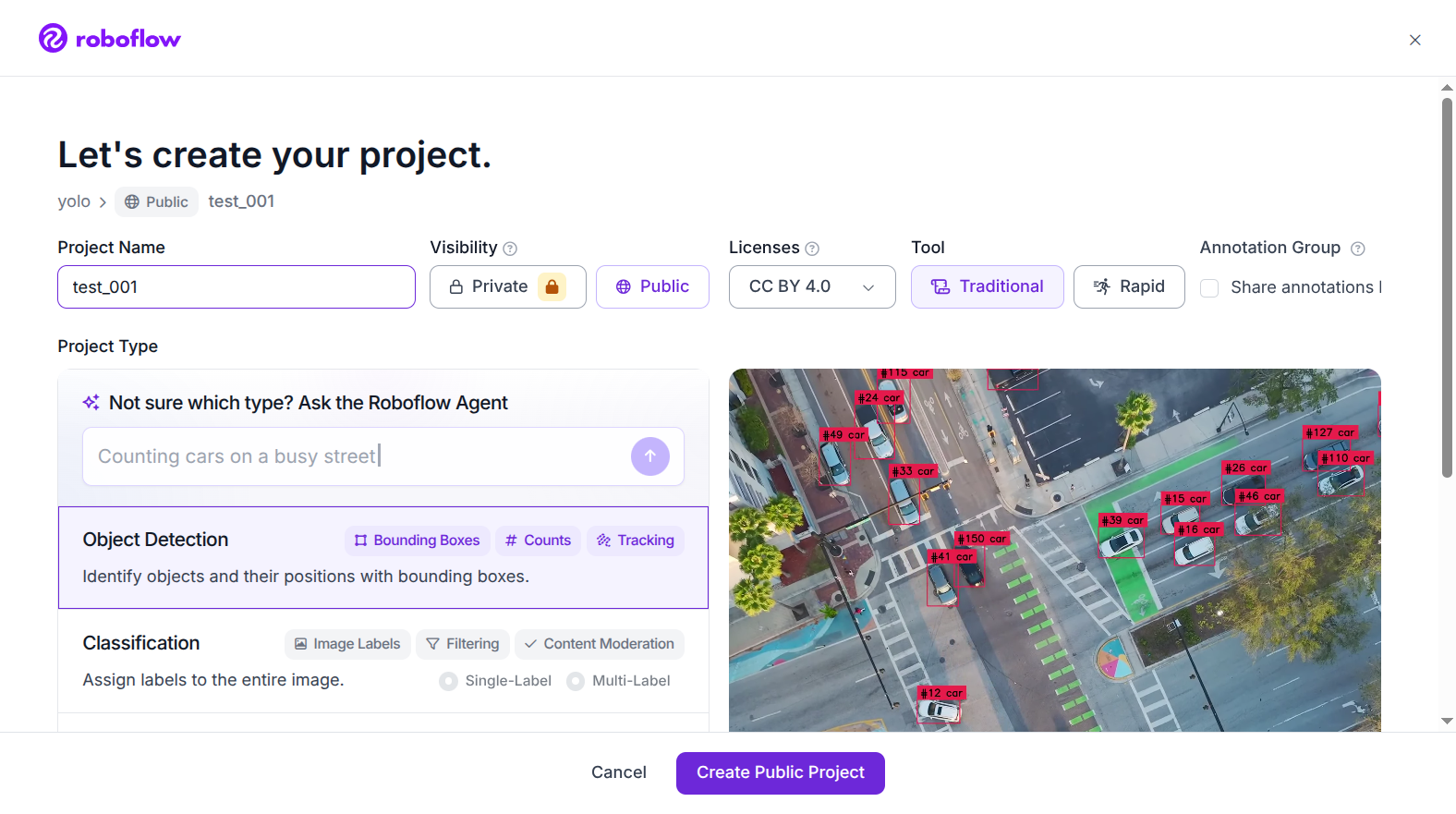
▲ 图 2:Roboflow New Project 弹窗 — Project Type 选择 Object Detection
2.2 上传图片
- 进入项目后,点击左侧 Upload Data
- 拖拽图片文件夹或点击选择文件(支持 JPG/PNG)
- 等待上传完成,点击 Finish Uploading
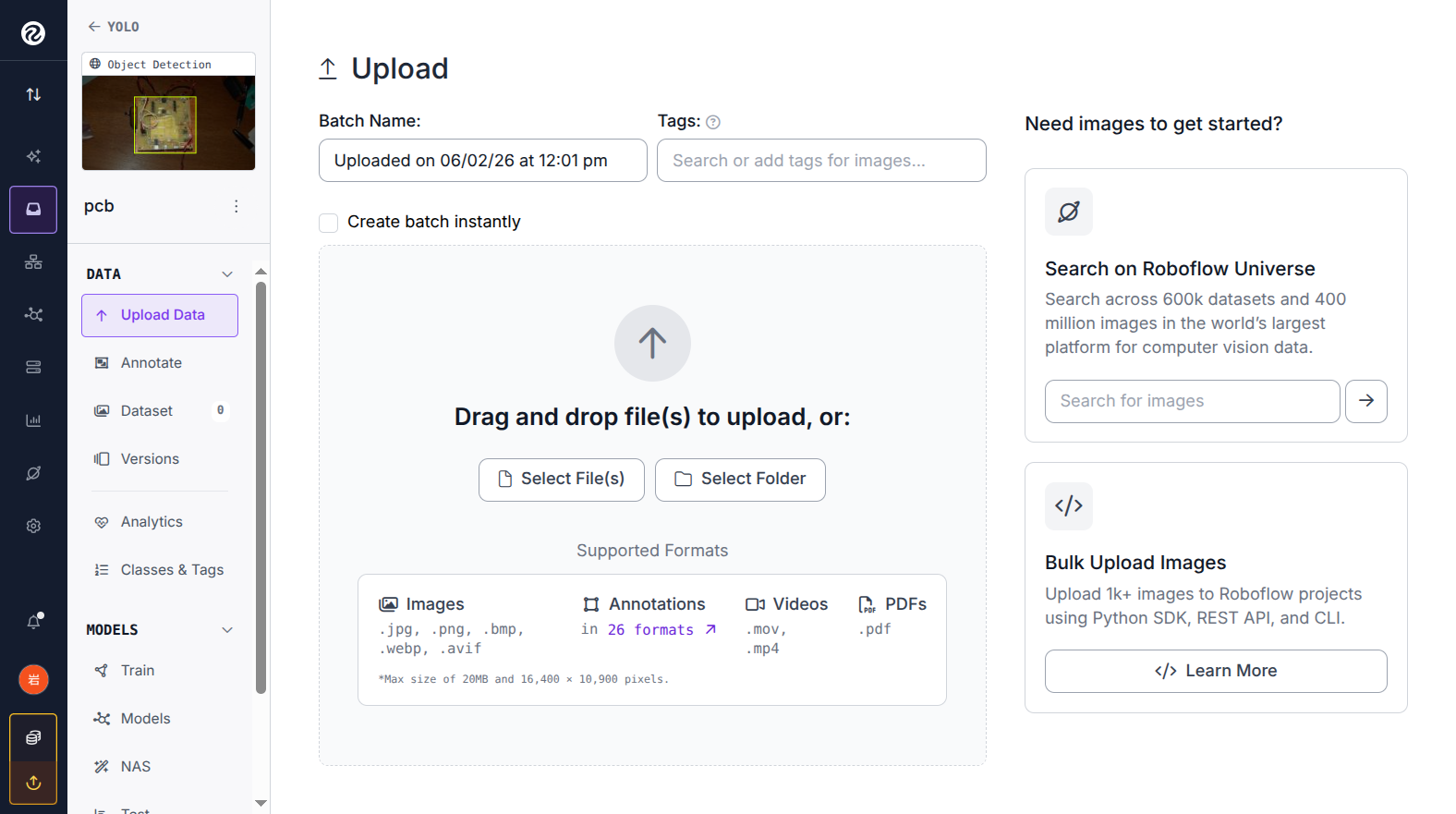
▲ 图 3:Roboflow Upload Data 页面 — 图片上传完成,点击 Finish Uploading
2.3 采集建议
| 变量 | 建议覆盖范围 |
|---|---|
| 拍摄距离 | 30cm / 50cm / 80cm / 100cm |
| 拍摄角度 | 正对、左偏 15°/30°、右偏、上偏 |
| 光照条件 | 室内顶灯、室外自然光、侧光、暗光 |
| 最少数量 | 50 张以上(100 张以上效果更好) |
数据标注规范
3.1 类别定义
在 Roboflow 标注界面,使用以下类别(以充电口检测为例):
| 类别名 | 框住的目标 | 用途 |
|---|---|---|
charging_port | 整个充电口(含外框) | YOLO 检测定位 |
DC_hole | DC+ 和 DC- 大孔(各一个框) | PnP 位姿估计关键点 |
PE | PE 接地孔 | PnP 位姿估计关键点 |
DC_hole 标注两个框。代码中通过 x 坐标排序区分左右(x 较小的为 DC+)。
3.2 标注操作步骤
- 进入 Annotate 页面,选择一张图片
- 按 B 键进入画框模式
- 拖拽鼠标画矩形框,松开后在弹出框中选择类别
- 每张图标注 4 个框:1 个
charging_port+ 2 个DC_hole+ 1 个PE - 按 → 进入下一张
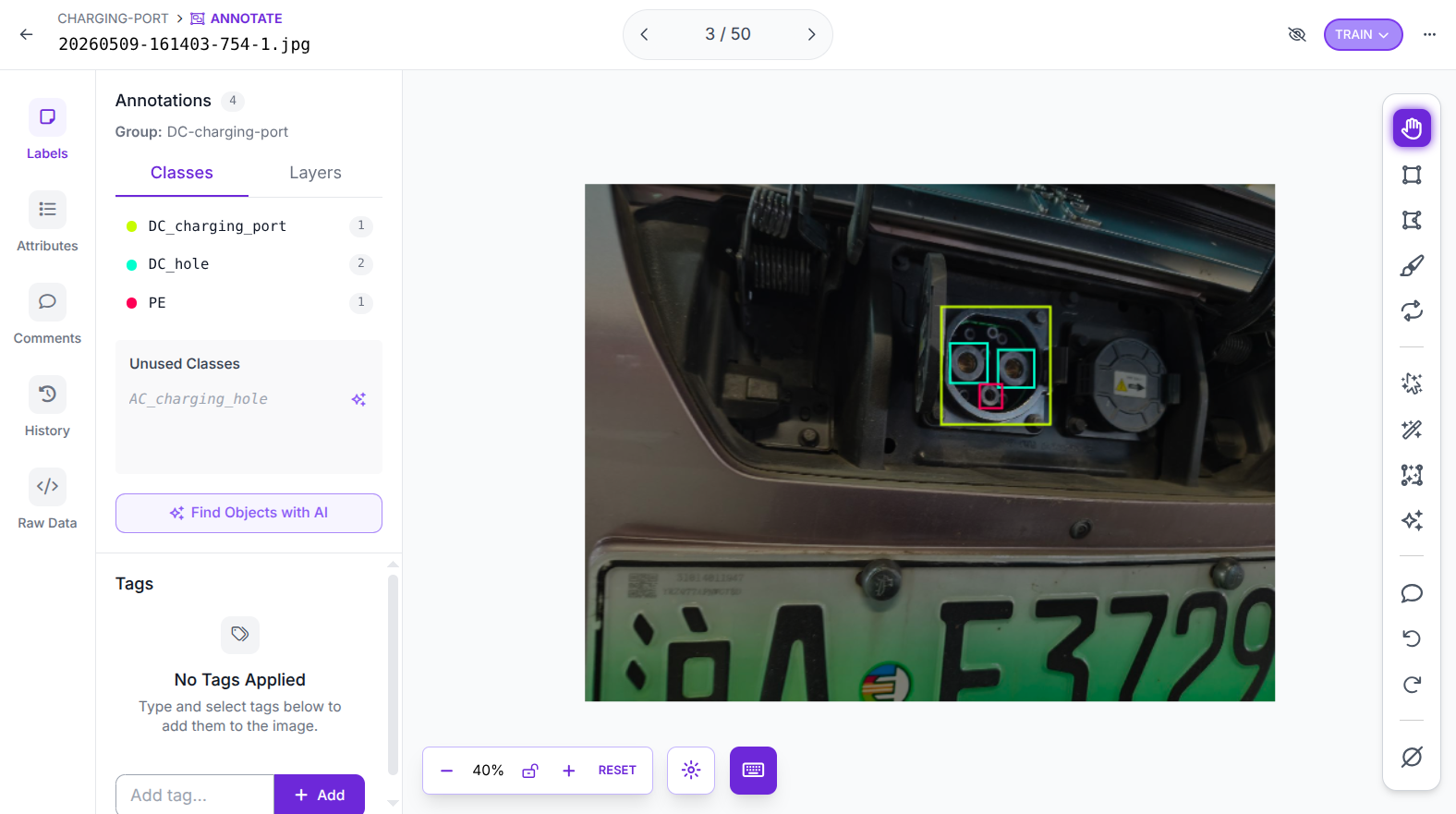
▲ 图 4:一张已完成标注的充电口照片 — 4 个框分别标记 charging_port / DC_hole×2 / PE
3.3 快捷键
| 快捷键 | 功能 |
|---|---|
| B | Bounding Box 画框模式 |
| → / ← | 下一张 / 上一张 |
| Ctrl + Z | 撤销 |
| Esc | 取消当前操作 |
| Delete | 删除选中的框 |
3.4 标注质量要求
- 框应贴合目标边缘,不要留太多空白
charging_port框住整个圆形充电口及其外环DC_hole框住孔的外圆边缘- 确保每张图的 4 个框都标完再翻页
生成数据集 Version
Version 是数据集的快照,包含分割比例、预处理和数据增强配置。每次训练前必须生成一个 Version。
4.1 进入 Versions 页面
点击左侧菜单 Versions → 右侧表单填写配置
4.2 设置 Train/Test Split(步骤 2)
点击 Train/Test Split 右侧的 Edit,设置比例:
| 数据集大小 | 推荐比例 |
|---|---|
| 40~100 张 | Train 80% / Valid 20% / Test 0% |
| 100 张以上 | Train 70% / Valid 20% / Test 10% |
4.3 预处理配置(步骤 3)
保留以下两项默认设置,无需修改:
- Auto-Orient:自动校正手机照片的旋转方向
- Resize to 512×512:统一图片尺寸
4.4 数据增强配置(步骤 4)
点击 Augmentation → Edit,开启以下增强项:
| 增强项 | 推荐参数 | 作用 |
|---|---|---|
| Flip | Horizontal(水平翻转) | 模拟充电口镜像场景 |
| Rotation | -15° ~ +15° | 模拟相机轻微倾斜 |
| Brightness | -25% ~ +25% | 模拟不同光照条件 |
4.5 创建 Version(步骤 5)
- Maximum Version Size:选
3x(训练集图片数 × 3 倍增强) - 点击 Create,等待几秒生成完成
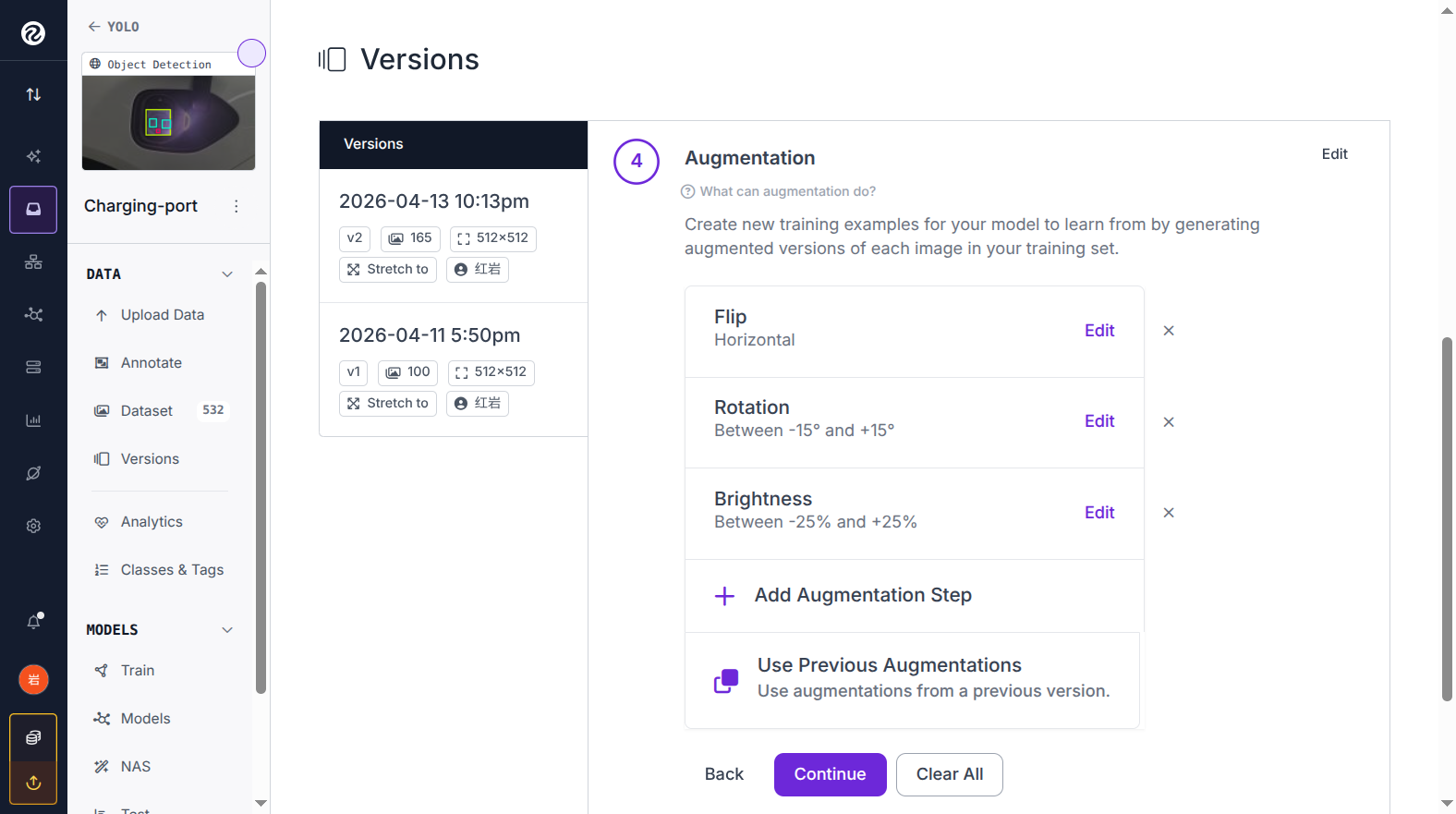
▲ 图 5:Roboflow Version 创建配置 — Train/Test Split + 预处理 + 数据增强 + 3x 上限
导出数据集到本地
5.1 进入 Version 页面
左侧菜单点击 Versions,选择刚生成的版本,点击右上角 Download Dataset
5.2 选择格式
- Format 选择 YOLOv11
- Download Options 选择 Download zip to computer
- 点击 Continue,浏览器自动下载 zip 文件
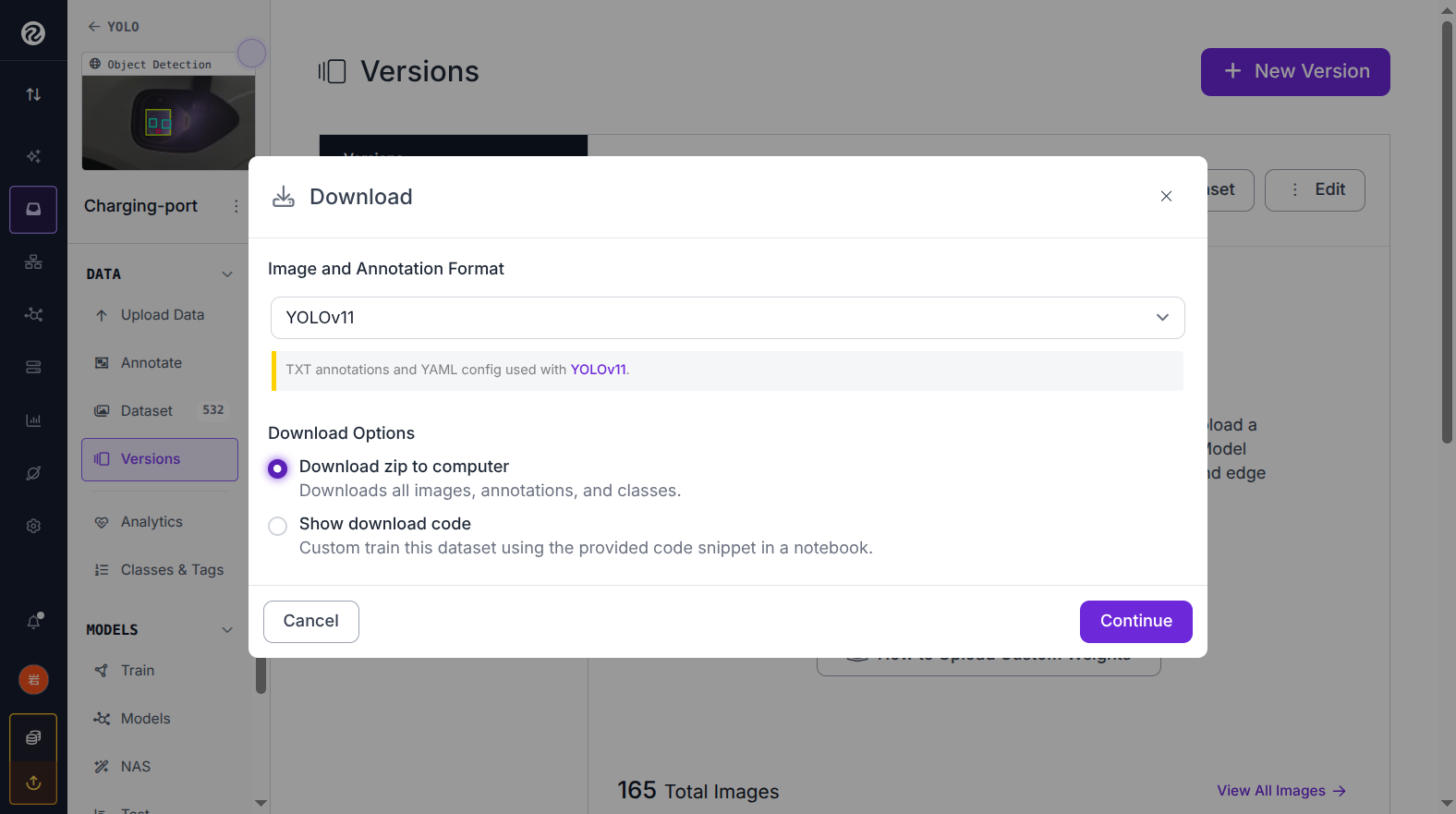
▲ 图 6:Download Dataset 弹窗 — Format 选 YOLOv11,download zip to computer
5.3 解压到指定目录
解压后目录结构如下:
修正 data.yaml 路径
Roboflow 导出的 data.yaml 使用相对路径,在本地训练时容易找不到文件,必须改为绝对路径。
6.1 打开 data.yaml
默认内容(相对路径,需要修改):
6.2 修改为绝对路径
用文本编辑器打开 data.yaml,将路径改为绝对路径:
cd 到数据集目录,然后运行 pwd 即可得到完整路径。
本地训练模型
7.1 创建训练脚本
在项目目录下创建 train.py:
7.2 运行训练
DC charging port),必须用引号包裹路径,或者将路径写在 Python 脚本中,不要在命令行直接拼接。
7.3 训练参数说明
| 参数 | 说明 | 建议值 |
|---|---|---|
| epochs | 训练总轮数 | 100(小数据集) |
| imgsz | 输入图片尺寸 | 512(与 Roboflow 预处理一致) |
| batch | 每批图片数量 | 16(CPU)/ 32(GPU) |
| patience | 早停耐心值 | 50(可选,防止过拟合) |
7.4 训练输出目录
解读训练结果
8.1 训练完成时的输出示例
8.2 关键指标含义
| 指标 | 全称 | 含义 | 目标 |
|---|---|---|---|
| P(Precision) | 精确率 | 检测到的框中,正确的比例 | > 0.9 |
| R(Recall) | 召回率 | 所有真实目标中,被检测到的比例 | > 0.9 |
| mAP50 | Mean Average Precision @IoU=0.5 | IoU≥0.5 视为正确时的平均精度,主要指标 | > 0.85 |
| mAP50-95 | Mean Average Precision @IoU=0.5:0.95 | 多 IoU 阈值平均,衡量定位精度 | > 0.5 |
8.3 结果评估
| mAP50 | 评价 | 建议 |
|---|---|---|
| > 0.95 | 优秀 | 可直接部署使用 |
| 0.85 ~ 0.95 | 良好 | 可用,建议补充更多数据 |
| < 0.85 | 待改进 | 增加数据量,检查标注质量 |
8.4 使用 best.pt 进行验证预测
常见问题 FAQ
Q1:预训练权重(yolo11n.pt)的作用是什么?Fine-tune 后还能识别原来的物体吗?
预训练权重的价值在于迁移学习能力,而不是"保留原有类别的记忆"。
用 COCO 数据集训练过的模型,其骨干网络(Backbone)已经学会了提取边缘、纹理、形状等通用视觉特征。Fine-tune 时,这部分能力被保留并迁移,使模型只需几十张图片就能学会识别充电口这类新类别。
Fine-tune 时,data.yaml 中 nc: 3 与原模型的 nc: 80 不一致,Ultralytics 会自动丢弃原有检测头并重新初始化。因此:
| Fine-tune 后 | 状态 |
|---|---|
| 骨干网络的视觉特征提取能力 | ✅ 保留(这是迁移学习的价值所在) |
| COCO 原有 80 类的识别能力 | ❌ 丢失(检测头被重建) |
Q2:标注 DC_hole 和 PE 对提升充电口识别精度有帮助吗?
对 charging_port 的检测精度几乎没有直接帮助,但有其独立用途。
| 类别 | 实际用途 | 是否必须 |
|---|---|---|
charging_port | YOLO 检测定位充电口位置 | ✅ 必须 |
DC_hole | PnP 位姿估计,计算充电口三维朝向,供机器人精准插枪 | 按需选择 |
PE | PnP 位姿估计关键点 | 按需选择 |
charging_port 即可。如果后续需要精准对准插枪(计算三维位姿),则 DC_hole 和 PE 是必要的关键点。
Q3:训练完后原本 YOLO 能识别的 80 类物体都不能识别了,怎么办?
这是正常现象(原因见 Q1)。工程上有三种应对方案:
Q3.1 保留两个独立模型(推荐)
这是工业界最常见的做法——专用模型比通用模型精度更高,按场景切换使用即可。
Q3.2 使用 YOLO-World(开放词汇检测)
YOLO-World 无需重新训练,直接用文字描述类别,80 类识别能力始终保留:
Q3.3 双模型并行推理
同时运行两个模型,合并输出结果:
Q4:收集到更多图片后,需要把所有图片重新训练一遍吗?
是的,每次都把所有标注好的图片放在一起全量训练,这是标准做法。如果只用新图片训练,模型会遗忘旧图片学到的知识,效果反而变差。
正确的迭代方式:以上一版 best.pt 为起点,用全量数据继续训练:
| 图片数量 | 预期效果 |
|---|---|
| 20~50 张 | 流程跑通,场景泛化差(换角度/光线可能失败) |
| 100~200 张 | 较稳定,覆盖主要场景变化 |
| 500 张以上 | 生产级别可靠性 |